The Limits of AI and Where Humans Shine
Part of a series
- AI-Assisted Engineering Series (6 of 10)
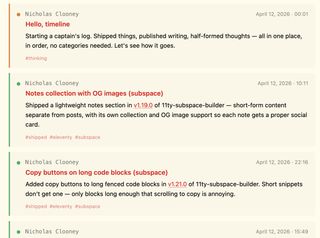
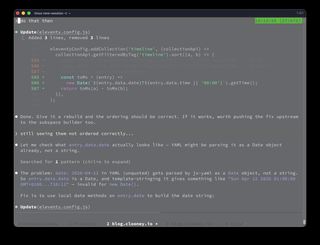
I hit a bug that looked too small to be interesting: entries on my timeline page were not sorted correctly within the same day.
The page had a date, a time, and a custom Eleventy collection sort. That sounds like the whole problem space. Sort by date plus time, reverse the collection for newest first, done. Instead, April 12 was rendering in a strange order: 00:01, 10:11, 22:16, 15:49, 22:20.
This became a useful little case study in how clever AI is, and where that cleverness breaks down. Claude worked hard, sounded confident, and kept missing the actual bug. Codex got there quickly by running tiny JavaScript checks instead of reasoning from vibes. The final fix still needed human steering: fix the data at source, then add a strong guard so neither human nor AI can reintroduce the mistake quietly.
The Bug
The screenshot that started this showed the timeline grouped by day, but not correctly sorted inside the day.
I started by asking Claude to inspect the timeline sorting logic.
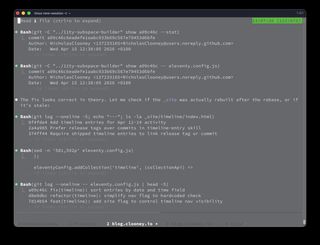
Claude started in the right area: the custom timeline collection and the generated timeline HTML.
The timeline entries looked like this:
---
title: Copy buttons on long code blocks (subspace)
date: 2026-04-12
time: "22:16"
tags:
- timeline
- shipped
- eleventy
- subspace
---
And the local Eleventy config had a custom timeline collection:
eleventyConfig.addCollection('timeline', (collectionApi) =>
collectionApi.getFilteredByTag('timeline').sort((a, b) => {
const toMs = (entry) =>
new Date(`${entry.data.date}T${entry.data.time || '00:00'}`).getTime();
return toMs(a) - toMs(b);
}),
);
The template then reversed the collection for newest-first display:
{% set logItems = collections.timeline | default([]) | reverse %}
At a glance this looks plausible. Sort ascending, reverse for display, and every entry has a date and time.
But that plausibility was the trap.
The Confident Wrong Turn
Claude's first round of debugging did what AI tools often do: it formed a reasonable hypothesis, changed the code to match that hypothesis, and then talked as if the fix was basically done.
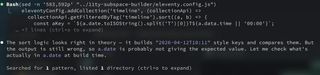
The attempted fix was to avoid constructing a full date string and instead add hours and minutes onto entry.date.getTime():
const toMs = (entry) => {
const [h = 0, m = 0] = String(entry.data.time || '00:00')
.split(':')
.map(Number);
return entry.date.getTime() + (h * 60 + m) * 60 * 1000;
};
That also looks reasonable. It even sounds cleaner in one sense: trust Eleventy's entry.date, then add the explicit timeline time.
The trouble is that this was still not really diagnosing the failure. It was replacing one implementation with another implementation that seemed more robust, without proving why the old one failed.
That is where AI confidence can be expensive. "Looks good to me" and "this should fix it by now" are only useful if the model has actually checked the assumption underneath them.
In this case, the assumption was: entry.data.date is a date-shaped string.
It was not.

Codex Took the Boring Route
Codex approached the same problem differently. It inspected the config, checked the generated HTML, and then ran tiny Node snippets against the exact YAML parsing behavior.
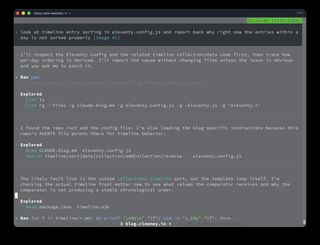
The key verification was this kind of check:
import yaml from 'js-yaml';
const doc = yaml.load('date: 2026-04-12\ntime: "22:16"\n');
const combined = String(doc.date) + 'T' + doc.time;
const parsed = new Date(combined);
console.log({
dateString: String(doc.date),
dateType: Object.prototype.toString.call(doc.date),
combined,
parsed: parsed.toString(),
ms: parsed.getTime(),
isNaN: Number.isNaN(parsed.getTime()),
});
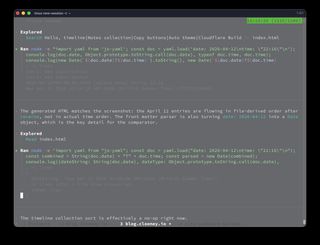
That produced the important shape of the bug:
{
dateString: 'Sun Apr 12 2026 01:00:00 GMT+0100 (British Summer Time)',
dateType: '[object Date]',
combined: 'Sun Apr 12 2026 01:00:00 GMT+0100 (British Summer Time)T22:16',
parsed: 'Invalid Date',
ms: NaN,
isNaN: true
}
The front matter said:
date: 2026-04-12
time: "22:16"
But in YAML, an unquoted ISO-looking date is not necessarily a plain string. js-yaml parses it as a JavaScript Date.
So this line:
new Date(`${entry.data.date}T${entry.data.time || '00:00'}`).getTime();
was not building this:
2026-04-12T22:16
It was building something more like this:
Sun Apr 12 2026 01:00:00 GMT+0100 (British Summer Time)T22:16
That is not a valid date string. getTime() returned NaN.
And when a JavaScript sort comparator returns NaN, it is treated like 0 for ordering purposes. The entries compare as equal, so their existing collection/file order is preserved. Then the template reverses that unsorted collection.
That is how I ended up with the visible order:
00:01, 10:11, 22:16, 15:49, 22:20
instead of:
22:20, 22:16, 15:49, 10:11, 00:01

The Human Part: Fix the Data at Source
Once Codex found the bug, the obvious engineering fix would have been to make the comparator handle both strings and Date objects.
That is a good defensive patch, but it did not feel like the whole answer. The real source of the surprise was the data:
date: 2026-04-12
That looks like a date string to a human author. To YAML, it is a timestamp-shaped scalar.
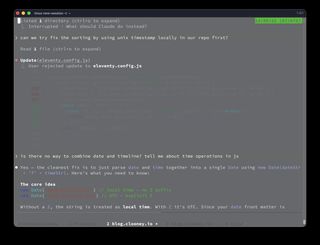
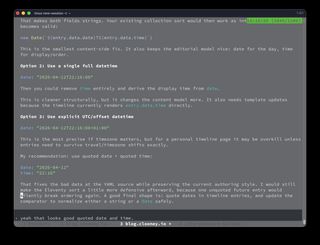
So I asked the more important question: can we fix the issue at source? Can we give better data in YAML?
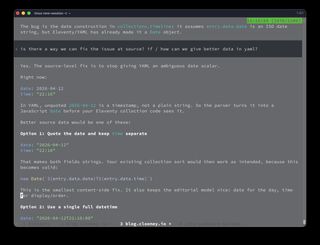
The answer was yes. Quote the date and keep the separate time field:
date: "2026-04-12"
time: "22:16"
That keeps both fields as strings. It also preserves the editorial model I wanted:
dateis the day of the entrytimeis the within-day ordering and display time- the timeline template can render both directly
There were other possible source shapes:
date: "2026-04-12T22:16:00"
or:
date: "2026-04-12T22:16:00+01:00"
Those are structurally cleaner in some systems, especially if exact timezone semantics matter. But for this site they would change the authoring model more than necessary. The minimal source-level fix was quoted date plus quoted time.
The Actual Patch
The final patch had three parts.
First, quote the timeline entry data:
date: "2026-04-12"
time: "22:16"
Second, make the collection sort defensive anyway:
const toIsoDatePart = (value) => {
if (typeof value === 'string') {
return value.split('T')[0];
}
if (value instanceof Date && !Number.isNaN(value.getTime())) {
return value.toISOString().split('T')[0];
}
return '';
};
const getTimelineSortKey = (entry) => {
const date = toIsoDatePart(entry?.data?.date) || toIsoDatePart(entry?.date);
const time =
typeof entry?.data?.time === 'string' && entry.data.time.trim()
? entry.data.time.trim()
: '00:00';
return `${date}T${time}`;
};
Then sort by that string key:
eleventyConfig.addCollection('timeline', (collectionApi) =>
collectionApi.getFilteredByTag('timeline').sort((a, b) => {
return getTimelineSortKey(a).localeCompare(getTimelineSortKey(b));
}),
);
String comparison works here because the key is deliberately ISO-shaped:
YYYY-MM-DDTHH:MM
For same-format date/time strings, lexical order is chronological order.
Third, add a build-time checker that fails loudly if a future timeline entry forgets to quote either field.
That checker has to scan the raw Markdown file before YAML parsing. Once YAML has parsed the front matter, the quote information is gone.
The validator extracts the front matter, reads top-level date: and time: fields, and checks whether the values are quoted:
const isQuotedYamlScalar = (value) => {
const trimmed = String(value || '').trim();
return (
/^"[^"]*"\s*(?:#.*)?$/.test(trimmed) || /^'[^']*'\s*(?:#.*)?$/.test(trimmed)
);
};
If a timeline entry is wrong, the build now fails with a message like:
Timeline entry front matter must quote date and time values so YAML does not coerce dates before sorting:
- timeline/2026-04-12-example.md: date must be quoted (expected date: "YYYY-MM-DD")
That last piece matters. It turns a subtle, cross-layer type bug into an immediate authoring error.
What This Says About AI
This was not a big bug. That is exactly why it was interesting.
Claude was not useless. It found relevant code, reasoned in the right area, and proposed changes that were plausible. But it struggled because it kept operating one layer above the real problem. It was trying to fix sorting without proving what the comparator was actually sorting.
Codex did better because it used the runtime as a source of truth. It did not just say "YAML might be parsing this weirdly." It ran js-yaml, printed the type, constructed the string, parsed it with new Date, and saw NaN. That small verification step collapsed the search space.
The lesson is not "Codex good, Claude bad." The lesson is that confidence is cheap, but instrumentation is expensive in the right way.
When an AI says:
- "this looks good to me"
- "this should fix it"
- "the logic is correct"
I now mentally append:
...UNLESS... It made assumptions without verifying.
which is such a human trait that we passed onto AI.
The TypeScript Thought
There is also a types angle here.
The bug existed because the code informally assumed:
entry.data.date: string
entry.data.time: string
But the runtime value was closer to:
entry.data.date: Date
entry.data.time: string
Plain JavaScript did not complain because there was nothing to complain with. The template rendered a readable date. The collection callback ran. The comparator returned a number-shaped value, except it was NaN, and the sort quietly preserved the existing order.
TypeScript would not automatically save this site on its own. The content comes from Markdown front matter, so the boundary is still runtime data. But TypeScript plus a real content schema would make the assumption explicit:
type TimelineEntry = {
date: string;
time: string;
};
Then the site could validate Markdown front matter into that shape before collection code ever touches it. A stronger future version of this would move the timeline validation out of ad hoc regexes and into a small typed content loader or schema check.
That said, the current checker is intentionally simple. It protects the exact mistake that happened:
- timeline entries must have
date - timeline entries must have
time - both must be quoted in source
- the build fails if they are not
Sometimes the minimal guard is better than a larger abstraction.
The Real Workflow
The final result was not just "AI fixed a bug."
It was a loop:
- Human noticed a visual ordering bug.
- Claude explored the area but got stuck in plausible fixes.
- Codex verified runtime assumptions with small Node checks.
- Human pushed for source-level data correctness.
- Codex applied the minimal fix in both local and upstream repos.
- The build gained a validator to prevent the same mistake later.
That is the AI workflow I trust most: not a magic answer box, but a fast partner that can inspect, test, and explain, while the human keeps pressure on the shape of the solution.
The funny thing is that the bug was caused by valid YAML doing exactly what YAML is allowed to do. The code was also doing something that looked reasonable. The template was doing what it had been told. Every layer was locally plausible.
The failure lived in the gap between them.
That is where good debugging happens. And, increasingly, that is where good AI collaboration happens too.
Appendix: How This Post Was Made
There is a meta layer to this post: it was made with Codex in the same session that did the investigation.
I provided the structure I wanted: a devlog about discovering a "simple" bug, a comparison between Claude struggling and Codex verifying assumptions, the human intervention around fixing the data at source, the TypeScript thought, and the build-time checker. Codex did most of the drafting from that outline, using the same technical details it had just worked through while debugging the timeline.
That feels both useful and slightly strange. The post is not a raw transcript. It is shaped, edited, and directed by me. But a lot of the actual prose was produced by the same tool that had just helped fix the bug. The writing process mirrors the engineering process: I set the direction, provided judgement, corrected details, and decided what belonged. Codex did the heavy lifting.
Side Note: Losing the Muscle
In What's Worth Keeping: On Humanness in the Age of AI, I wrote about losing some of my ability to write Chinese characters by hand because I grew up in the keyboard generation. I can still type Chinese fluently, but the physical memory of writing characters has faded.
I can imagine the same thing happening with fine writing. If I keep using AI to draft, rewrite, structure, and polish, maybe one day my own writing muscles get weaker. Maybe I lose some of the fluency that comes from sitting with a blank page and making sentences myself.
That may not be a terrible thing as long as the technology remains available. Keyboards changed handwriting. Spellcheck changed spelling. Search changed memory. But AI most likely will change everything we do.
So the uncomfortable question is what happens if the technology is not available. If the model is gone, the account is locked, the network is down, the company disappears, or the tool becomes too expensive, what remains?
Can I still write/work/code/create?
Can you?
Can we, as humans?
That is probably the deeper question underneath all of this.